

Kubernetes بهسرعت به یه استاندارد جدید برای استقرار و مدیریت نرمافزار توی بستر Cloud تبدیل شده. کوبرنتیز یه پلتفرم قدرتمند برای اجرای نرمافزار توی Cloud هست. یادگیری کوبرنتیز منحنی سختی داره. وقتی یه تازهکار تلاش میکنه که داکیومنت رسمی Kubernetes رو بخونه، خیلی گیج میشه. این نرمافزار قسمتهای مختلفی داره و تشخیص اینکه کدوم قسمت برای پروژه شما مناسبه میتونه سخت باشه. توی این پست سعی میکنم بهطور ساده Kubernetes مقدماتی رو توضیح بدم. ولی در عین سادگی سعی میشه یه دید کلی سطح بالا، از مهمترین اجزا و نحوه تطبیق اونا با هم ارائه بشه.
خب، همین اول کار بیاین یه نگاه به نحوه کارکرد سختافزار توی Kubernetes نگاه کنیم.
سختافزار در کوبرنتیز
Node
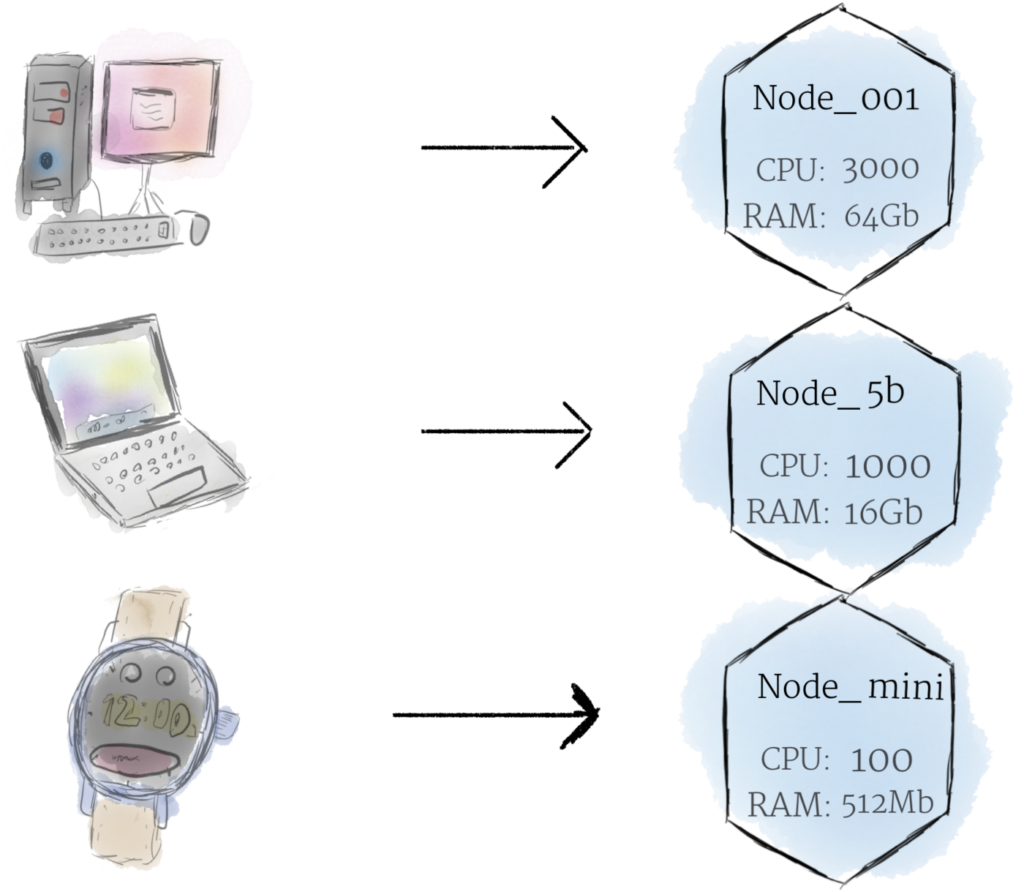
Node کوچکترین واحد سختافزار محاسباتی در Kubernetes هست. Node یه کامپیوتر فیزیکی یا مجازی توی Cluster شماست. در اکثر سیستمهای نرمافزاری، یه Node یه ماشین فیزیکی توی یه دیتاسنتر یا یه ماشین مجازی (VM) هست که روی یک ارائهدهنده ابری (Cloud Provider) مثل Google Cloud میزبانی میشه. اجازه ندید که محدودیتهای نرمافزاری و سختافزاری جلوی درک شما از Node رو بگیره. بهصورت تئوری، تقریباً از هر چیزی میتونین یه Node بسازین.
در نظرگرفتن هر نوع کامپیوتری به عنوان یک Node به ما امکان میده که بدون در نظر گرفتن محدودیتهای سختافزاری و نرمافزاری به Node نگاه کنیم. بهجای نگرانی در مورد ویژگیهای دستگاه، میتونیم به سادگی هر دستگاه رو بهعنوان مجموعهای از منابع CPU و RAM در نظر بگیریم که توی کلاستر کوبرنتیز میشه ازش استفاده کرد. به این صورت، بدون هیچ محدودیتی، هر دستگاهی میتونه جایگزین هر دستگاه دیگهای توی یک کلاستر Kubernetes بشه.
Cluster
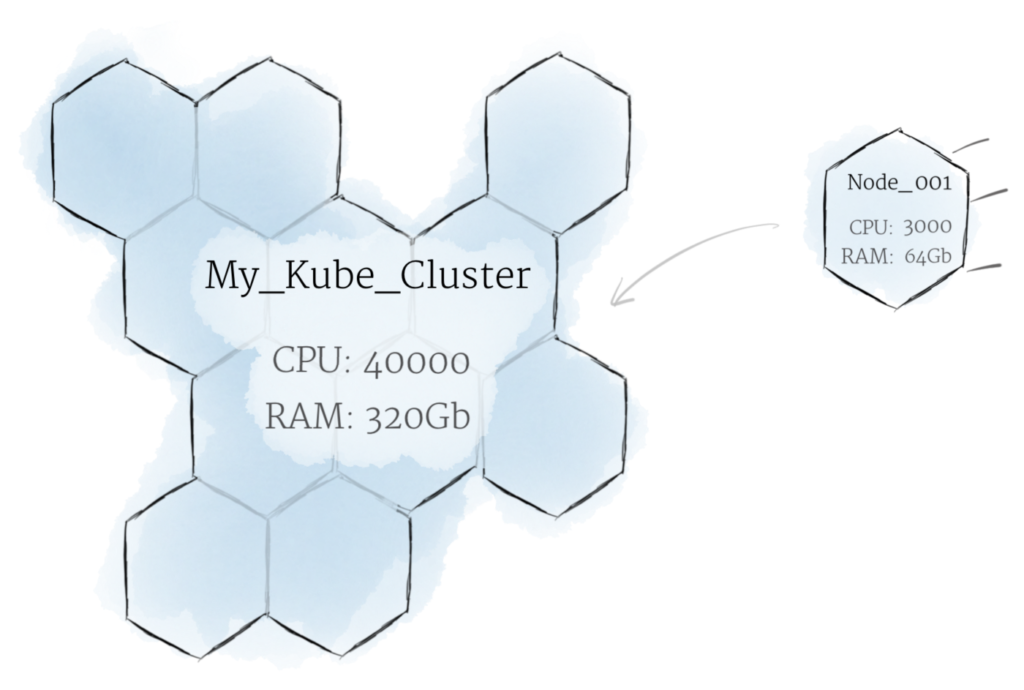
بله، داشتن چند تا Node میتونه مفید باشه. اما این روش Kubernetes نیست. توی کوبرنتیز، به جای کارکرد جداگانه هر Node، همه نودها بهعنوان یه مجموعه پردازشی و با هم کار میکنن. به این مجموعه متشکل از چند نود که بهعنوان یه کل واحد کار میکنن، یه Cluster گفته میشه.
توی کوبرنتیز، Nodeها منابعشون رو با هم ترکیب میکنن تا یه سیستم قدرتمندتر رو تشکیل بدن. وقتی یه برنامه Application رو روی یه کلاستر مستقر میکنین، تقسیم بار پردازشی بین نودهای اون کلاستر بهصورت هوشمند انجام میشه. وقتی یه Node رو حذف میکنین یا Node دیگهای به کلاستر اضافه میکنین، کلاستر در صورت لزوم نحوه تقسیم بار بین نودها رو تغییر میده. دیگه برای برنامه نویس و صاحب برنامه فرقی نمیکنه که توی یه لحظه مشخص، دقیقا کدوم نود داره برنامه رو اجرا میکنه.
اگر این نوع سیستم شبه کندو، شما رو به یاد بورگ از فیلم Star Trek میندازه، تنها نیستین. “بورگ” اسم پروژه داخلی گوگل بود که Kubernetes بر اساس اون ساخته شده.
Persistent Volume
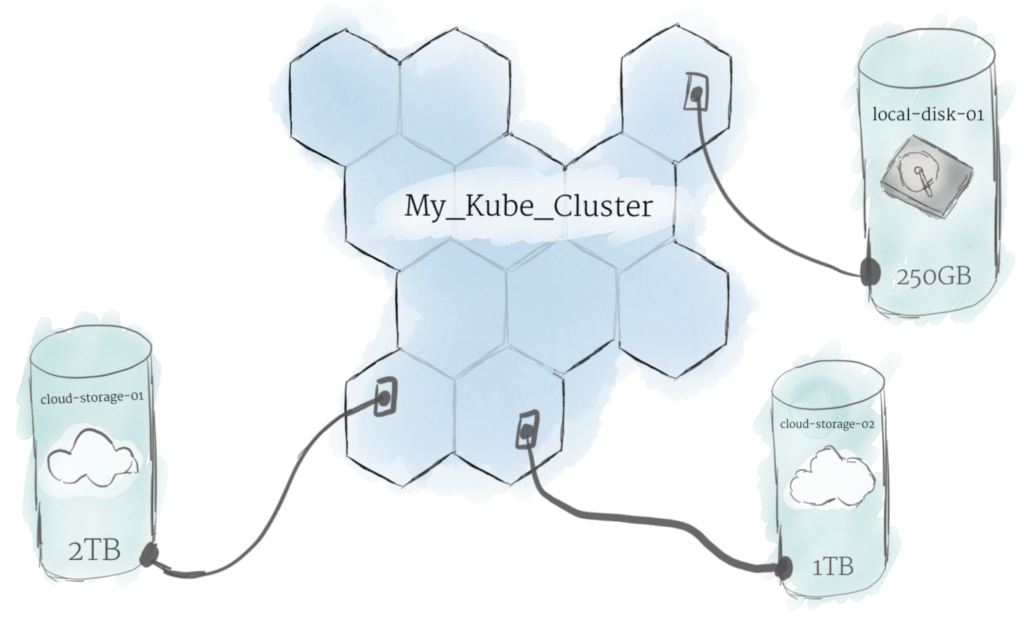
همونطوری که گفته شد، وقتی برنامه روی کلاستر اجرا میشه، معلوم نیست دقیقا توی هر لحظه داره روی کدوم Node اجرا میشه. بنابراین نمیشه دادهها رو توی هر مکان دلخواهی از فایل سیستم نودها ذخیره کرد. اگه برنامهای روی نودی که داره روش اجرا میشه، دادهها رو ذخیره کنه، اما بعدش به یه نود دیگه منتقل بشه، دیگه فایل جایی که برنامه انتظار داره، نیست. به همین دلیل، توی کوبرنتیز حافظه سنتی هر نود صرفا بعنوان حافظه موقت Cache برای نگهداری دیتا استفاده میشه. اما نمیشه انتظار داشت که دادههایی که روی هر نود بهصورت محلی ذخیره شده، روی نودها باقی بمونن.
برای ذخیره دائمی دیتا، کوبرنتیز از درایوهای پایدار Persistent Volumes استفاده میکنه. همونطوری که گفته شد، توی کوبرنتیز، کلاستر به خوبی منابع RAM و CPU نودها رو ادغام و مدیریت میکنه. اما داستان برای ذخیره دائمی فایل اینجوری نیست. برای ذخیرهسازی دائمی، باید درایوهای محلی یا ابری رو برای ذخیرهسازی دائمی دیتا به کلاستر متصل کرد. درایوهای پایدار Persistent Volumes فایل سیستمهایی هستن که میشه اونا رو بدون وابستگی به نود خاصی، به کل کلاستر متصل کرد.
نرمافزار در کوبرنتیز چیست؟
Container
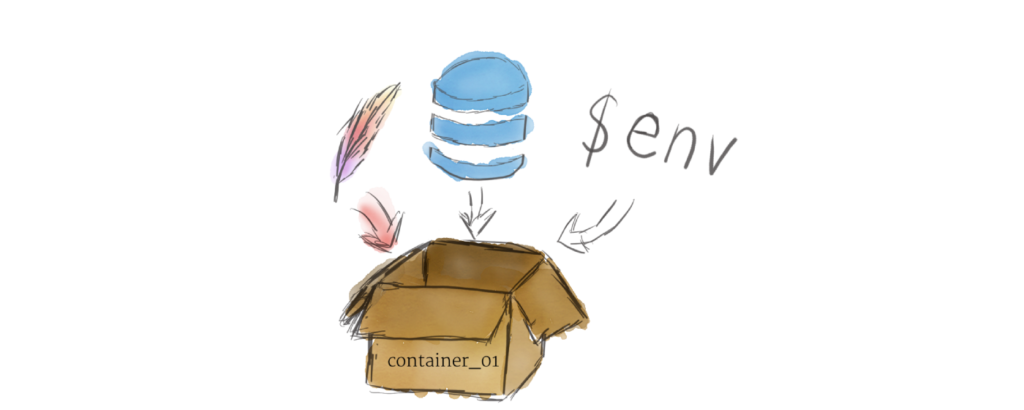
برنامههای در حال اجرا در Kubernetes بهصورت کانتینر لینوکس بستهبندی میشن. کانتینرها استانداردی کاملاً پذیرفتهشده در دنیای کامپیوتر هستن و ایمیجهای آماده زیادی وجود دارن که میتونن توی Kubernetes مستقر و اجرا بشن.
کانتینرسازی Containerization به شما این امکان رو میده که محیطهای اجرایی لینوکس مستقل ایجاد کنین. هر برنامه و تمام وابستگیهای اون (dependencies) رو میشه توی یک فایل واحد جمع کرد و توی اینترنت به اشتراک گذاشت. هرکسی میتونه کانتینر رو دانلود کرده و اون رو در زیرساختهای خودش به آسونی مستقر کنه. ایجاد یک کانتینر میتونه با برنامهریزی (بجای نصب دستی) هم انجام بشه، و اجازه میده ادغام مستمر و تحویل/توسعه مستمر نرم افزار شکل بگیره.
چندین برنامه رو میشه با هم توی یه کانتینر اجرا کرد. اما توی تولید نرمافزار، در صورت امکان باید سعی کنین هر پروسه رو بهعنوان یه کانتینر اجرا کنین. داشتن چندین کانتینر کوچک خیلی بهتره تا داشتن یه کانتینر بزرگ. اگه هر کانتینر هدف مشخصی داشته باشه و یه کار بهخصوص رو انجام بده، آپدیت کردن و عیبیابی اون آسونتره.
Pod

Kubernetes مستقیما کانتینرها رو اجرا نمیکنه. کانتینرها توی یک یا چند ساختار سطح بالاتر به نام pod قرار میگیرن. هر کانتینر منابعش رو با سایر کانتینرهای اون پاد به اشتراک میذاره و با اونا توی یه شبکه داخلی قرار میگیره. در واقع هر کانتینر با سایر کانتینرهای همون پاد ارتباط برقرار میکنه، مثل اینکه روی یه دستگاه قرار گرفتن. در عین حال هر کانتینر نسبت به کانتینرهای سایر پادها ایزوله هستن.
پادها بهعنوان واحدهای قابل تکثیر و همسانسازی (Replication) توی کوبرنتیز استفاده میشن. اگه کاربران برنامه شما زیاد بشن و یه پاد نتونه بار پردازشی لازم رو هندل کنه، میشه Kubernetes رو پیکربندی کرد تا در صورت لزوم، کپیهای جدیدی از پاد شما توی کلاستر ایجاد و مستقر کنه. حتی وقتی که سیستم زیر بار نیست، روش استاندارد اینه که از هر پاد چند نسخه داشته باشیم تا در صورت لزوم بار رو مدیریت کنه و در صورتی که یکی از پادها دچار مشکل شد، پادهای دیگه ادامه کار سیستم رو بهعهده بگیرن.
پادها میتونن چندین کانتینر رو توی خودشون جا بدن. اما در صورت امکان باید این تعداد رو محدود کنین. از اون جایی که پادها بهعنوان یه واحد پردازشی در صورت نیاز تکثیر و کم میشن، همه کانتینرهایی که توی پاد قرار گرفتن هم همراه پاد تکثیر میشن. حتی اگه سیستم نیازی به تکثیر اون کانتینر خاص نداشته باشه، همراه بقیه کانتینرهای اون پاد، اون کانتینر هم تکثیر میشه. این اتفاق میتونه باعث اتلاف منابع سختافزار و ایجاد هزینههای غیرضروری مازاد بشه. برای حل این مشکل، پادها باید تا حد امکان کوچک بمونن و فقط شامل یه کانتینر اصلی برای اجرای یه پروسه خاص و چند کانتینر کمکی جانبی (Side Cars) برای کمک به کانتینر اصلی باشن.
Deployments
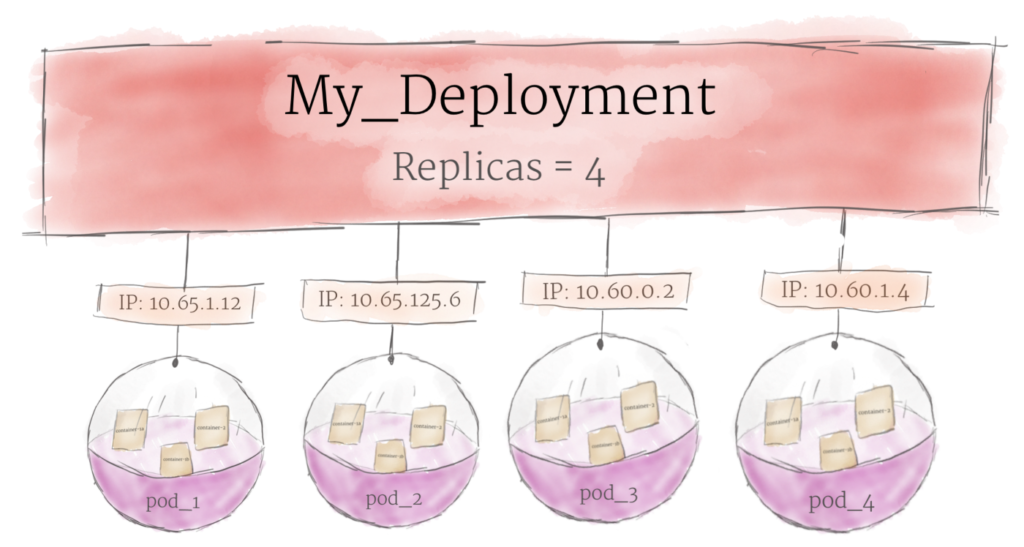
اگرچه پادها واحد اصلی محاسباتی Kubernetes هستن، اما معمولاً مستقیماً روی یک کلاستر راهاندازی نمیشن. در عوض، پادها معمولاً توسط یک لایه دیگه مدیریت میشن: Deployment
هدف اصلی یک Deployment اینه که اعلام کنه چند نسخه از یک پاد باید در حال اجرا باشه. وقتی که یک Deployment به Cluster اضافه میشه، بهصورت خودکار تعداد پادهای درخواستی رو اجرا میکنه و بعد اونا رو مانیتور میکنه. اگر یک pod دچار مشکل بشه و از بین بره، Deployment به طور خودکار اون را دوباره ایجاد میکنه.
با استفاده از Deployment، لازم نیست بهصورت دستی با پادها سر و کله بزنین. شما فقط لازمه وضعیت مورد نظر سیستمتون را اعلام کنین و Deployment همه چیز رو بهطور خودکار برای شما مدیریت میکنه.
Ingress
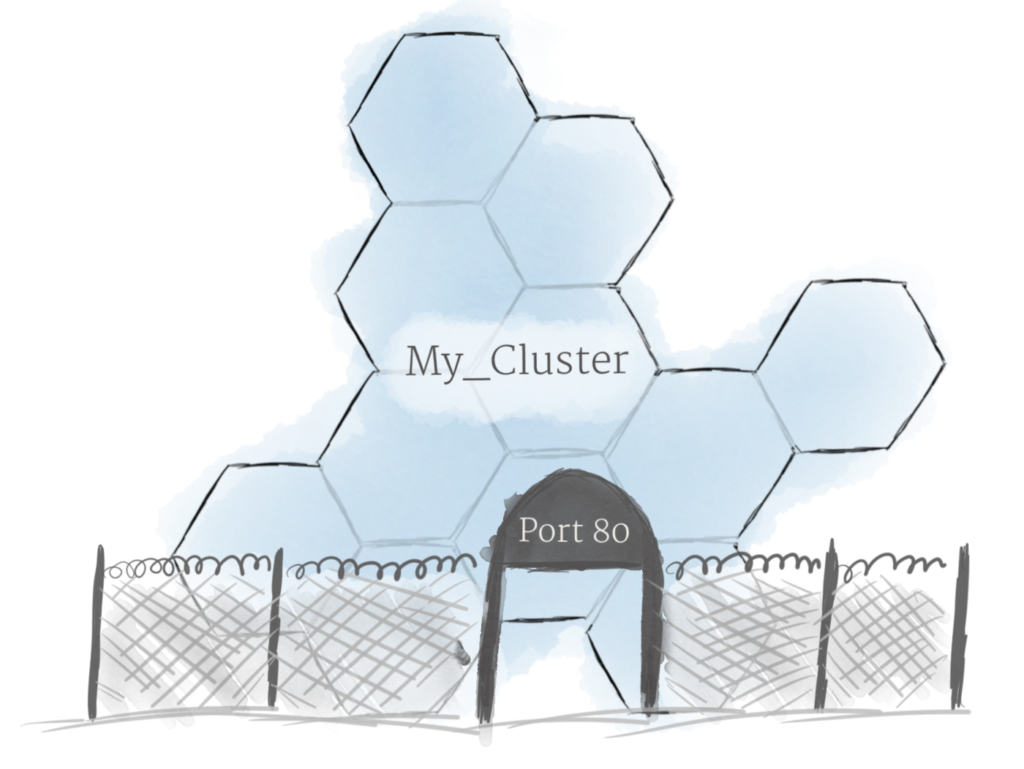
با استفاده از مفاهیمی که در بالا توضیح داده شد، میتونین یک Cluster از Nodeها ایجاد کنین و Deploymentهایی برای اجرای پادها روی Cluster ها ایجاد کنین. حالا فقط یه مشکل باقیمونده که باید حل بشه: اجازه دادن به ترافیک خارجی به برنامه شما.
بهطور پیشفرض، Kubernetes پادها رو از دنیای خارج جدا میکنه. اگر میخواین با یک سرویس در حال اجرا توی یک پاد ارتباط برقرار کنین، باید یک کانال برای ارتباط باز کنین. به این فرایند Ingress گفته میشه.
راههای زیادی برای افزودن Ingress به کلاستر وجود داره. رایجترین راه، اضافهکردن یک کنترلکننده Ingress یا یک LoadBalancer است. مقایسه دقیق این دو راه خارج از بحث این پست هست، اما باید توجه داشته باشین که مدیریت Ingress چیزیه که باید قبل از کار با Kubernetes براش تصمیم بگیرین.
قدم بعدی کوبرنتیز
چیزی که در بالا توضیح داده شد یک توضیح خیلی ساده از Kubernetes هست، اما اصول اولیهای رو که برای شروع کار نیاز دارین در اختیار شما قرار میده. حالا که قسمتهای تشکیل دهنده سیستم رو درک میکنین، وقت اینه که از این مفاهیم برای استقرار یک برنامه واقعی استفاده کنین.
برای اجرای لوکال Kubernetes ،Minikube یک کلاستر مجازی روی سیستم شما ایجاد میکنه. اگر میخواین یک سرویس Cloud رو امتحان کنین، Google Kubernetes Engine کلی آموزش کوبرنتیز برای شروع داره.
اگه توی دنیای کانتینرها و زیرساختهای وب تازه وارد هستین، پیشنهاد میکنم 12 Factor App methodology رو مطالعه کنین. این متد بهترین شیوههایی رو که باید در زمان طراحی نرمافزار برای اجرا در محیطی مثل Kubernetes در نظر داشت، شرح میده.